





Product request
You are looking for a solution:
Select an option, and we will develop the best offer
for you


طلباتك أوامر

 | قبل 31 عامًا، كان التلفزيون الذي يستجيب للأوامر الصوتية في فيلم Back to the Future, Part II مجرد فكرة خيالية، مثله مثل السيارة الطائرة. أمّا الآن فأصبح معظم الناس يملكون أجهزةً لها واجهات صوتية. وفي هذا المقال، سنشرح كيف تعمل تقنية التعرف على الكلام، وسنريك كيف تعمل برامج المساعد الصوتي، وسنأخذ مساعد Google مثالًا. |
التجارب الأولى في مجال التعرف على الصوت
 | من الأمور المفاجئة في هذا الصدد أن أول منتج منزلي يحتوي على واجهة صوتية كان لعبة أطفال: ففي عام 1987، كان بإمكان الأطفال تدريب لعبة جولي دول (Julie Doll) لتتعرف على أصواتهم، وكانت تستجيب لمحفِّزات مثل إطفاء النور وقراءة الكتب التي أتت مصحوبةً بها بصوتٍ عالٍ. |
وبعدها ببضع سنوات، ظهر أول برنامج إملاء مُزوَّد بتقنية التعرف على الصوت، وظهرت أيضًا أجهزة تساعد ضِعاف البصر وغير القادرين جسديًا على استخدام لوحات مفاتيح الكمبيوتر.
وفي 1990، كان سعر رخصة DragonDictate، وهو أول "كاتب صوتي"، يبلغ 9,000 دولار أمريكي.
Later in the وبعدها في التسعينيات، ظهرت واجهات صوتية أخرى لتسهيل الأعمال المختلفة. فعلى سبيل المثال، قدمت شركة BellSouth بوابة VAL لتتعامل تلقائيًا مع الاستفسارات الهاتفية وتشرح خدمات الشركة للعملاء. لكن للأسف افتقرت هذه الحلول الأولى إلى الدقة، وكانت تتطلب تدريبًا لفترات طويلة.
| مع مرور الوقت تطورت التكنولوجيا، وأصبح كثير من الأجهزة "الذكية" المتاحة اليوم مزودًا بواجهات صوتية. فأصبحت الشركات المُصنِّعة للمنتجات التكنولوجية تدمج تقنية التعرف على الصوت في أجهزتها لتُسهِّل على عملائها التعامل معها من دون استخدام اليدين، فالتحدث أسهل من الكتابة وأنت منغمس في أنشطتك اليومية، كقيادة السيارة أو المشي أو مشاهدة التلفزيون. |

الأنظمة الحديثة المتاحة اليوم للتعرف على الكلام تساعدنا في العثور على المعلومات وكتابة النصوص وحجز المواعيد، وتُستخدَم في أنظمة الخدمة الذاتية التفاعلية: مثل خدمات الدعم الفني.
كيف تعمل تقنية التعرف على الكلام؟
تستقبل الأجهزة الصوت بطريقة مختلفة عن البشر، فبدلًا من الكلمات، تسمع الأجهزة إشارةً متصلةً تسري فيها الأصوات بسلاسة، والجهاز يرصد العبارة الواحدة كإشاراتٍ مختلفةٍ باختلاف النبرات أو أصوات المتحدثين. ونظرًا إلى مدى التنوع الشاسع في طرق كلام البشر، فإن دقة أنظمة التعرف على الصوت لم تبلغ 100% بعد. المهمة الرئيسية لخوارزميات التعرف على الصوت هي تمييز الكلام بغضّ النظر عن اختلافات النطق بين المتحدثين ومن دون التأثر بضوضاء الخلفية وغيرها من عوامل التشويش. |  |
عناصر نظام التعرف على الكلام
تتألف أنظمة التعرف على الكلام من 4 مكونات:
- وحدة تنقية الصوت (إزالة ضوضاء الخلفية)
- النموذج الصوتي (لتمييز أصوات الكلام)
- النمط اللغوي (لتوقع تسلسلات الكلمات ذات الاحتمالية الأعلى)
- وحدة فك الترميز (لجمع بيانات النموذج الصوتي مع النمط اللغوي من أجل تقديم النتيجة النهائية)
في كل مرحلة، تمر الإشارة الصوتية بسلسلة من التحولات، وتفاصيلها في ما يلي.
1. تنقية الصوت
المهمة الأولى لنظام التعرف على الكلام هي تقييم جودة المُدخلات الصوتية وفصل الإشارة المرغوب بها عن التشويش الصوتي أو الضوضاء. ويمكن استخدام وسائل مختلفة لفلترة الصوت من ضوضاء الخلفية وفقًا لطبيعة الأصوات غير المرغوب بها.
عزل الضوضاء
يستعين نظام التعرف على الكلام بطرق متعددة لعزل الضوضاء: منها وضع ضوضاء اصطناعية تشمل تسجيلات لأصوات شائعة (مثل صوت محرك سيارة أو رياح أو مطر) "ليُعلِّم" النموذج الصوتي كيف يُميِّز الصوت المطلوب من الضوضاء الخارجية. ومع ذلك، عندما يسمع النظام لاحقًا ضوضاء غير مألوفة له فإنه غالبًا ما يرسل رسالة "خطأ".
وتعتمد بعض الطرق الأخرى لعزل الضوضاء على حلول متمثلة في مكونات الأجهزة. فبعض الهواتف الذكية مزودة بجهازَي ميكروفون: الأول في مقدمة الجهاز لالتقاط الكلام ومعه الضوضاء، والثاني في ظهر الجهاز، ويلتقط الضوضاء المحيطة. ونظريًا، فإن كل المطلوب فعله لاستقبال إشارة واضحة هو ببساطة طرح إشارة الصوت الثانية من الأولى.
الأصوات الخارجية
تمييز صوت واحد من وسط أصوات مجموعة من المتحدثين أصعب من تمييزه من بين مجموعة من الأصوات الأخرى. فلتمييز صوت متحدث واحد من بين مجموعة من الأصوات، يتكيَّف النموذج الصوتي مع صوت المستخدم ويتذكر السمات المُميِّزة لنطقه.
2. تقسيم إشارة الكلام إلى كلمات
المهمة التالية لنظام التعرف على الصوت هي تمييز كل كلمة على حدة من بين تسلسل صوتي متصل وتحديد معناها.
على المستوى الأبسط، يمكن اعتبار الكلام سلسلةً متغيرةً من الأصوات والسكتات. ويمكن فهم السكتات على أنها "فواصل" بين الكلمات.
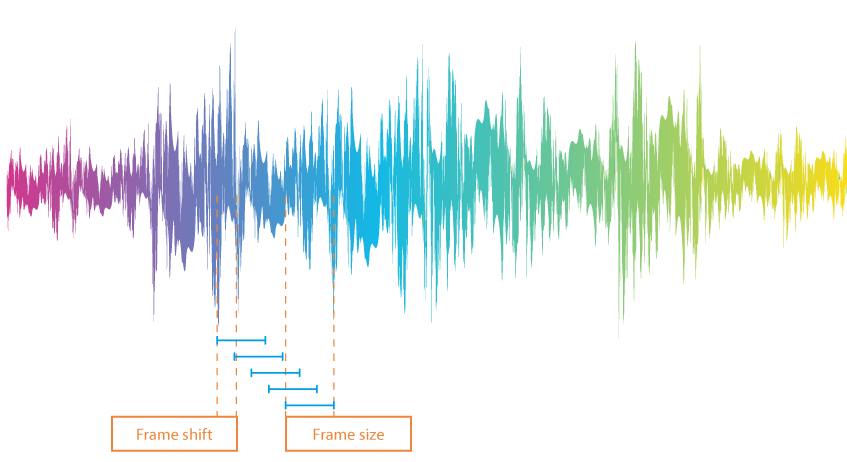
لتحليل إشارة الكلام على هيئة كلمات وفواصل بين الكلمات، يُقسَّم التسجيل الصوتي أولًا إلى إطارات (Frames)، وهي أقسام صغيرة طول الواحد منها 10 ملي ثانية، وهذه الإطارات ليست متتابعةً بالضبط، فنهاية كل قسم تُركَّب على بداية القسم الذي يليه.
ولتحديد الإطارات التي تحتوي على أصوات بشرية، يفرض النظام حدًّا فاصلًا، فتُعتبَر القيم التي تتجاوز هذا الحد كلمات، فيما تُعتبَر القيم التي تقِلُّ عنه سكتات. وتُوجد خيارات متعددة لتحديد قيمة الحدّ الفاصل:
- تحديد رقم ثابت (يمكن استخدام هذا الثابت عندما يُولَّد الصوت بالطريقة نفسها وفي الظروف نفسها).
- تحديد عدد من القِيَم التي تدل على السكوت (إذا شغل السكوت مدةً مُعتبَرةً من التسجيل).
- تحليل الإنتروبيا (Entropy Analysis)، وهذا يتطلَّب تحديد مدى "تذبذب" الإشارة ضمن نطاق الإطار. وعادةً ما يكون مقدار التذبذب أقل في السكتات.
من بين هذه الطرق الثلاث، يُعتبَر تحليل الإنتروبيا الأعلى كفاءةً رغم عيوبه. فعلى سبيل المثال، قد تقل الإنتروبيا عند تطويل الحروف المتحركة، وقد تزيد بفعل ضوضاء طفيفة. ولحل هذه المشكلة، يستفيد النظام من مفهومَي "أقل فرق بين الكلمات" و"أقل طول للكلمة"، فتجمع الخوارزمية بين القطع شديدة القِصَر، وتعزل الضوضاء.
3. تفسير الكلمات
 | غالبًا ما تُجمَع الشبكات العصبية الاصطناعية (Neural Networks) مع جهاز يحتوي على نماذج ماركوف (Markov) خفيّة، وتُستخدَم لتفسير الكلمات. |
نماذج ماركوف الخفيّة في أثناء البحث في نصوص أدبية تعود إلى أوائل القرن العشرين، افترض عالم الرياضيات "أندري ماركوف" أن احتمالية وجود حرف مُعيَّن تعتمد على الحرف الذي يسبقه، واتضح أن هذه القيمة تظل ثابتةً في الأجزاء المختلفة من النص الواحد. | 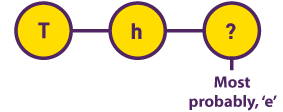 |
تختلف مؤشرات الاحتمالات بين كاتب وآخر، وهذا يتيح الاستفادة من نماذج ماركوف في كشف السرقات الأدبية.
في نماذج ماركوف، يتألف النص من متواليات من الحروف، بينما يُعامَل الكلام كمتوالية من الرموز الصوتية. صحيح أن كل رموز النصوص المكتوبة أصواتها معروفة، لكن التسجيلات الصوتية تحتوي على تمثيلات للرموز الصوتية، وليس على الرموز الصوتية نفسها، فصوت حرف "الرّاء" مثلًا يُنطَق بطرق متعددة.
والجهاز لا يعرف الرمز الصوتي عند نطقه، فهو لا يلتقط سوى مُعامِلات الموجة الصوتية عند لحظة زمنية معينة. وبالإضافة إلى تقدير احتمالية صدور رمز صوتي معين، يتولى النظام مهمة ربط الرموز الصوتية بتنويعات الإشارات المناسبة التي تناظرها.
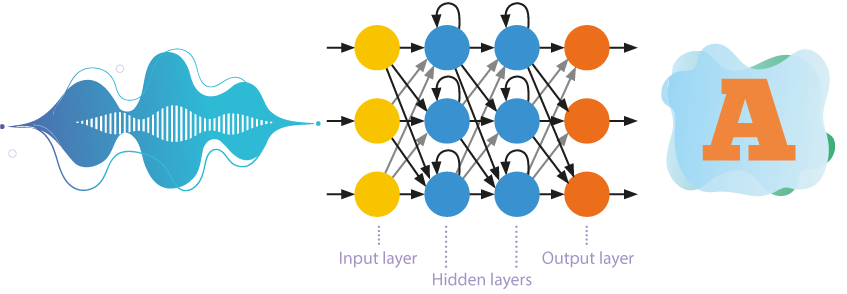
التغذية الأمامية (Feedforward) للشبكات العصبية الاصطناعية
حتى وقتٍ قريب، كانت الشبكات العصبية الاصطناعية ذاتيّة التعلم ذات الطبقات الكثيرة تُستخدَم غالبًا في التعرف على الكلام.
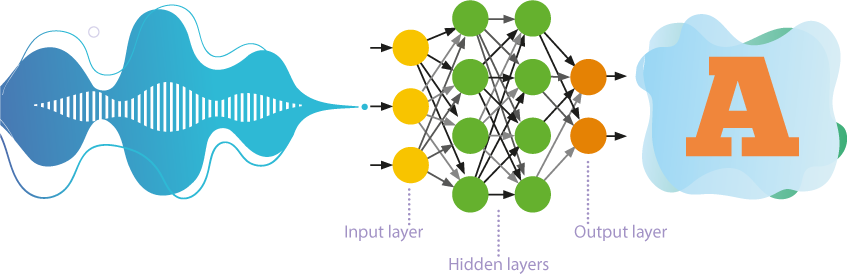
- هذه الشبكات تعالج المعلومات في اتجاه واحد فقط: من الخلايا العصبية المتصلة بالمُدخَلات إلى الخلايا العصبية المتصلة بالمُخرجات.
- تُوضع طبقات متعددة من الخلايا العصبية الاصطناعية في ترتيب هرمي بين المُدخَلات والمُخرجَات، فالمعاملات المرتبطة بالتفاصيل الأكثر شمولًا تتبع المعاملات المرتبطة بالتفاصيل الدقيقة البسيطة.
- يُقصَد بالتعليم الذاتي، أو التعليم من دون إشراف، أن الشبكة العصبية الاصطناعية تتعلم حلّ المشكلات من دون تدخّل خارجي. ويكشف هذا المنهج طبقاتٍ مخفيةً بين عناصر عينة تدريب الشبكة.
والنتيجة هي مجموعة من الاحتمالات لصدور رمز صوتي مُعيَّن، وتُقارَن بتوقُّع نموذج ماركوف، وهكذا يُحدَّد الصوتُ المنطوق بدقة عالية.
الشبكات العصبية الاصطناعية المتكررة (Recurrent Neural Networks)
أنظمة التعرف على الكلام تتطور بالتدريج لتتجاوز مرحلة استخدام نماذج ماركوف الخفيّة المُبسَّطة، فقد أصبحت النماذج الصوتية تعتمد أكثر فأكثر على الشبكات العصبية الاصطناعية المتكررة، فتُستخدَم الذاكرة الداخلية مع الانتشار الخلفي (Backpropagation) لتسمح بالتعرف على الكلام بكفاءةٍ أعلى.
والخلايا العصبية لا تتلقى المعلومات من الطبقة التي تسبقها وحسب، بل وتستقبل نتائج معالجتها هي لهذه المعلومات، وهذا يسمح بأخذ ترتيب البيانات بعين الاعتبار.
4. التعبير
مبدأ تمييز العبارات والجُمَل يشبه كثيرًا فك ترميز الكلمات. في السابق، كانت النماذج من نوع N-gram تُستخدَم في هذه المهمة، حيث تُحدَّد احتمالية صدور الكلمة وفقًا لما يسبقها من كلمات عددها N (وعادةً ما تساوي N ثلاث كلمات) اعتمادًا على تحليل أجزاء كبيرة من النص. |  |
أدى التعلُّم العميق (Deep Learning) وتطور الشبكات العصبية الاصطناعية المتكررة إلى تحسين النموذج اللغوي تحسينًا كبيرًا، وسمح له بأن يأخذ سياقات الكلام بعين الاعتبار. وأدى أيضًا إلى تلاشي القيد المتمثل في استخدام (N) من الكلمات السابقة لا أكثر.
أصبحت النماذج اللغوية قادرةً على تخمين الكلمات المفقودة أو غير المُتعرَّف عليها لعدد من الأسباب. وقد اتضح أن هذا مهم خاصةً للّغات التي تتسم بعشوائية بترتيب الكلمات، مثل اللغة الروسية، حيث إن التوقع لم يعتمد على الكلمات السابقة وحسب، بل وعلى العبارة بأكملها.
هكذا تعمل أنظمة التعرف على الكلام، لكن لا يكفي أن تفهم ما تناولناه: فليكون النظام مفيدًا، يجب أن يكون قادرًا أيضًا على الاستجابة للأوامر التي يتلقّاها، فيجيب عن الأسئلة ويفتح التطبيقات ويدير الوظائف الأخرى. وتتولى برامج المساعد الصوتي هذه المهام.
التعرف على الكلام في جهاز استقبال MAG425A
 | جهاز استقبال MAG425A مزود بجهاز تحكم يعمل بالصوت وبرنامج مساعد Google. وتوفر الواجهة الصوتية تجربة مستخدم جديدةً تمامًا. من الوظائف الأساسية للمساعد الصوتي:
|
ما هو مساعد Google؟
مساعد Google هو مساعد صوتي افتراضي قُدِّم لأول مرة في مؤتمر Google I/O في عام 2016 بكاليفورنيا. ومثل مساعد Siri الذي تقدمه Apple، ومساعد Alexa الذي تقدمه Amazon، ومساعد Cortana الذي تقدمه Microsoft، يقدم مساعد Google معلومات سياقية بحسب طلب المستخدم، ويستطيع أن يؤدي وظائف معينة (مثل إدخال جمل البحث، وإعداد التنبيهات، وفتح التطبيقات، والتحكم في تشغيل المحتوى).
مساعد Google يستعين بالتعلم على أساس الكمبيوتر وتكنولوجيا المعالجة الطبيعية للّغات (NLP)، ويستطيع النظام تمييز الأصوات والكلمات والأفكار في الكلام.
يعمل المساعد الصوتي على مليار جهاز ويدعم أكثر من 30 لغة، لكن نسخة Android TV لا تعرف حتى الآن سوى 12 لغة: الإنجليزية والفرنسية والألمانية والهندية والإندونيسية والإيطالية واليابانية والكورية والبرتغالية والإسبانية والسويدية والفيتنامية.

كيف يعمل مساعد Google؟
أولًا، يسجل التطبيق الكلام الذي يلتقطه. وتفسير الكلام يتطلب قدرةً حاسوبيةً كبيرة، لذا يرسل مساعد Google الطلبات إلى مراكز بيانات Google، وعندما تصل إليها البيانات الصوتية، تُقسَّم الإشارة المتصلة إلى أصوات. وتتولى خوارزمية مساعد Google مهمة البحث في قواعد البيانات عن أصوات الكلام لتحدد أيّ الكلمات أكثر تطابقًا مع مجموعة الأصوات المُسجَّلة.
وبعد ذلك يُميِّز النظام الكلمات "الرئيسية" من كلام المستخدم ويقرِّر كيف يستجيب. فعلى سبيل المثال، إذا التقط مساعد Google كلمات مثل "الطقس" و"اليوم"، فإنه سيخبرك بتوقعات حالة الطقس اليوم.
 | ترسل خوادم Google المعلومات إلى الجهاز، ويؤدي مساعد Google المهمة المطلوبة، أو يقدم الإجابة صوتيًا. |
تُطوِّر Google طريقة عمل مساعد Google ليستطيع تمييز الكلام والأوامر مباشرةً على جهاز المستخدم. فطوَّرت الشركة نموذجًا جديدًا للتعرف على الكلام وفهمه، وهذا بالاستفادة من قدرات الشبكات العصبية الاصطناعية المتكررة. وصغَّرت الشركة حجم قاعدة بيانات النماذج الصوتية مئات المرات، ليستطيع نموذج الذكاء الاصطناعي الذي يعتمد عليه تطبيق المساعد أن يعمل داخليًا على جهاز المستخدم من دون حاجة إلى الاتصال بخوادم الشركة. فالتطبيق يعالج الكلام على الفور من دون تأخير يُذكَر، ومن دون الحاجة إلى الاتصال بالإنترنت. . |  |
الجيل الجديد من مساعد Google يستجيب للطلبات بسرعة تصل إلى 10 أضعاف ما كانت عليه. ونماذج هاتف Pixel الذكي التي تقدمها Google تدعم مساعد Google منذ عام 2019، وفي المستقبل، سيصبح التطبيق متاحًا على الأجهزة الأخرى أيضًا.
اليوم، أصبحت واجهة Android TV الصوتية متاحةً، ليس للشركات ذات الميزانيات المليونية وحسب، بل ولمُشغِّلي خدمات IPTV/OTT المحليين أيضًا. وهذه فرصة ممتازة لمُشغِّلي الخدمات لجذب جماهير جديدة وتسهيل عمليات البحث عن المحتوى وتشغيل الخدمات وتحسين تجربة المستخدم من أجل التفوق على المنافسين.
*Google وAndroid TV علامتان تجاريتان لشركة Google LLC.
Recommended

كيفية إنشاء بيئة Staging بشكل صحيح لاختبار تحديثات IPTV
أي تحديث في نظام IPTV يؤثر على أكثر من مكون واحد ويمكن أن يؤثر على المصادقة وتشغيل القنوات وEPG وVoD وDRM واستقرار الشبكة.

مجالات B2B لـ IPTV: من الفنادق إلى التلفزيون المؤسسي
أصبحت تقنية IPTV تتجاوز بشكل متزايد حدود أعمال المشغلين التقليدية والتلفزيون الموجه للمستهلكين. بالنسبة لقطاع B2B – من الفنادق ومراكز الأعمال إلى المؤسسات الطبية والمكاتب المؤسسية – أصبح IPTV أداة للخدمات والتواصل وإدارة الانتباه.

تسجيل الدخول الموحّد في IPTV: تبسيط الوصول دون المساس بالأمان
لقد تجاوز سوق IPTV وOTT منذ فترة طويلة فكرة أن المحتوى يُشاهَد على شاشة واحدة فقط.
