





Product request
You are looking for a solution:
Select an option, and we will develop the best offer
for you


Dileğin Benim İçin Emirdir

 | Otuz bir yıl önce, Geleceğe Dönüş, Bölüm II filminde sesli komutlara yanıt veren bir TV, uçan bir araba kadar fantastik bir fikirdi, neredeyse herkesin sesli arayüzlü cihazlara erişimi var. Bu makalede, Google Asistan'ı örnek olarak kullanarak konuşma tanımanın nasıl çalıştığını açıklayacağız ve sesli asistanların nasıl çalıştığını göstereceğiz. |
Ses tanımada ilk deneyler
 | Şaşırtıcı bir şekilde, sesli arayüze (VI) sahip ilk ev ürünü bir oyuncaktı. 1987'de çocukların konuşmasını tanımak için eğitilebilen Julie bebeği piyasaya sürüldü. Julie uyaranlara ışığı kapatmak ve onunla birlikte gelen kitapları yüksek sesle okumak gibi tepkiler verdi. |
Birkaç yıl sonra, görme engelliler ve fiziksel kısıtlamalar nedeniyle bilgisayar klavyesini kullanamayanlar için cihazlara ek olarak ilk ses tanıma dikte yazılımı ortaya çıktı.
1990'da, ilk ‘sesli daktilo‘ olan DragonDictate lisansı 9.000 dolara mal oldu.
Later in the Daha sonra 1990'larda, iş süreçlerini otomatikleştirmek için diğer sesli arayüzler tanıtıldı. Örneğin, BellSouth'un VAL portalı telefon sorgularını işledi ve müşterilere şirketin hizmetleri hakkında bilgi verdi. Maalesef bu ilk çözümler hatalıydı ve uzun süreli eğitim gerektiriyordu.
| Teknoloji zaman içinde istikrarlı bir şekilde gelişti ve bugün, tüketicilerin kullanımına sunulan ‘akıllı’ cihazların çoğu sesli arayüzlerle donatılmıştır. Teknoloji ürünleri üreticileri, müşterilerine daha fazla kullanım kolaylığı ve eller serbest kullanım sunmak için cihazlarına ses tanıma özelliğini dahil etti. Araba sürerken veya işe gidip gelirken veya TV'nizin önündeyken konuşmak, günlük aktivitelerin ortasındayken yazmaktan daha kolaydır. |

Günümüz konuşma tanıma sistemleri, bilgileri bulmamıza, metinleri yazıya dökmemize ve randevuları planlamamıza yardımcı olur. Teknik destek hizmetleri gibi etkileşimli self servis sistemlerde kullanılırlar.
Konuşma tanıma nasıl çalışır?
Cihazlar konuşmayı insanlardan farklı algılar. Cihaz, izole edilmiş kelimeler yerine seslerin birbirine düzgün bir şekilde aktığı sürekli bir sinyal duyar. Cihaz, farklı tonlamalarla telaffuz edilen veya farklı konuşmacılar tarafından seslendirilen bir ifadeyi farklı sinyaller olarak algılayacaktır. İnsan konuşmasındaki yüksek derecede değişkenlik nedeniyle, ses tanıma doğruluğu henüz %100'e ulaşmamıştır. Ses tanıma algoritmalarının temel görevi, konuşmacının telaffuz özelliklerine veya arka plan gürültüsünün ve diğer parazitlerin varlığına bakılmaksızın söylenenleri yorumlamaktır. |  |
Konuşma tanıma sisteminin unsurları
Konuşma tanıma sistemleri dört bileşenden oluşur:
- ses temizleme modülü (arka plan gürültüsünü gidermek için)
- akustik bir model (konuşma seslerini ayırt etmek için)
- dil kalıbı (en olası kelime dizilerini tahmin etmek için)
- kod çözücü (nihai sonucu sağlamak için akustik modelden gelen veri çıktısını dil kalıbı ile birleştirmek için)
Ses sinyali her aşamada bir dizi dönüşümden geçer. Bunlar hakkında aşağıda daha fazla bilgi edinebilirsiniz.
1. Ses temizleme
Konuşma tanıma sisteminin ilk görevi, ses girişinin kalitesini değerlendirmek ve istenen sinyali ses parazitinden veya gürültüden ayırmaktır. İstenmeyen sesin doğasına bağlı olarak, arka plandaki gürültüden konuşmayı filtrelemek için farklı yaklaşımlar kullanılabilir.
Gürültü bastırma
Konuşma tanıma sisteminde gürültüyü bastırmanın birkaç yolu vardır. Bunlardan biri, akustik modele sesi arka plan gürültüsünden ayırt etmeyi 'öğretmek' için, yaygın insan yapımı seslerin kayıtları da (örneğin, bir araba motorunun, rüzgarın veya yağmurun sesi) dahil olmak üzere yapay gürültüyü sisteme tanıtmaktır. Ancak sistem daha sonra tanıdık olmayan bir gürültüyle karşılaştığında model büyük olasılıkla bir 'hata' mesajı gönderecektir.
Diğer gürültü bastırma yaklaşımları donanım çözümlerine dayanır. Bazı akıllı telefonlar iki mikrofonla donatılmıştır: Cihazın ön tarafında bulunan ilk mikrofon, parazitli konuşmayı yakalar, arkadaki ikinci mikrofon ise ortamdaki arka plan gürültüsünü alır. Teoride, net bir sinyal elde etmek için yapmanız gereken tek şey, ikinci ses sinyalini birinciden çıkarmaktır.
İkincil sesler
Aynı anda birkaç kişi konuşurken belirli bir sesi ayırt etmek, konuşmayı konuşma dışı (ikincil) seslerden ayırt etmekten daha zordur. Akustik model, tek bir konuşmacıyı diğer seslerden izole etmek için kullanıcının sesine uyum sağlar ve telaffuzunun özelliklerini hatırlar.
2. Konuşma sinyalini kelimelere bölme
Ses tanıma sisteminin bir sonraki görevi, sürekli bir ses akışında tek tek kelimeleri seçip anlamlarını belirlemektir.
En temel düzeyde konuşma, değişen sesler ve sessizlikler olarak görülebilir. Sessizlikler kelime ‘ayırıcılar‘ olarak anlaşılabilir.
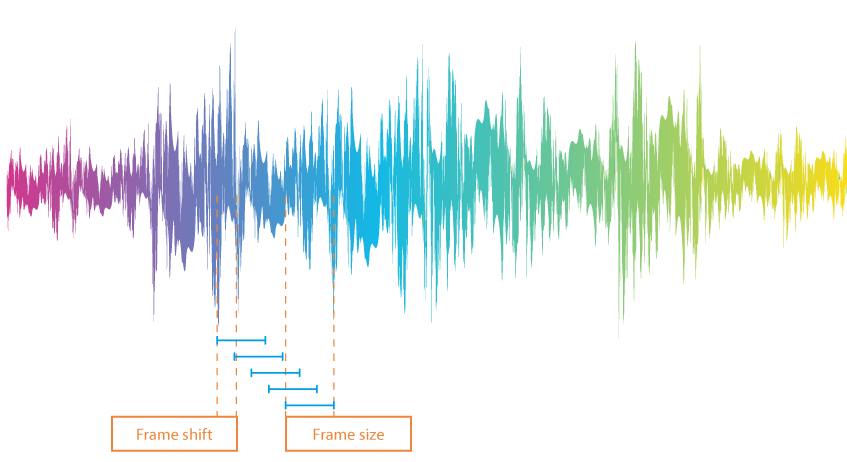
Konuşma sinyalini kelimeler ve kelime ayırıcılar açısından analiz etmek için, bir ses kaydı öncelikle çerçevelere, yani yaklaşık 10 ms uzunluğundaki küçük bölümlere ayrılır. Bu çerçeveler tam anlamıyla ardışık değildir: Bir bölümün sonu diğerinin başlangıcının üzerine yerleştirilmiştir.
Sistem, çerçevelerden hangilerinin insan sesi içerdiğini belirlemek için bir sınır belirler. Sınırın üzerindeki değerler kelime olarak kabul edilirken, altındaki değerler sessizlik olarak anlaşılmaktadır. Sınır değerini ayarlamak için birkaç seçenek vardır:
- Sabit olarak ayarlama (bu sabit, ses aynı şekilde ve aynı koşullar altında üretildiğinde kullanılabilir).
- Sessizliğe karşılık gelen bir dizi değerin tanımlanması (sessizlik kaydın önemli bir bölümünü kaplıyorsa).
- Entropi analizi yapmak (bu, sinyalin belirli bir çerçeve içinde ne kadar güçlü ‘salındığını’ belirlemeyi gerektirir. Kaydın sessiz kısımları için salınımların genliği genellikle daha düşüktür).
Üçü arasında entropi analizi, kusurları olsa da en güvenilir olanı olarak kabul edilir. Örneğin entropi sesli harfler çekildiğinde azalabilir ya da hafif bir gürültüyle artabilir. Sorunu çözmek için, 'kelimeler arasındaki minimum mesafe' ve 'minimum kelime uzunluğu' olmak üzere iki kavram tanıtılmıştır. Algoritma, çok kısa olan parçaları birleştirir ve gürültüyü kesip ayırır.
3. Kelimelerin yorumlanması
 | Çoğu zaman, gizli Markov modellerini içeren bir aparatla birleştirilen sinir ağları, kelimeleri yorumlamak için kullanılır. |
Gizli Markov modelleri Matematikçi Andrey Markov, 20. yüzyılın başlarındaki edebi metinleri araştırırken, başlangıçta bir harfin ortaya çıkma olasılığının kendisinden önceki harfe bağlı olduğunu varsaydı. Bu değerin aynı metnin farklı bölümlerinde sabit kaldığı ortaya çıkmıştır. |  |
Olasılık göstergeleri her yazar için benzersizdir. Bu, intihali tespit etmek için Markov modellerini kullanmayı mümkün kılar.
Markov modellerinde, basılı metin karakter dizilerinden oluşurken, konuşma bir fonem dizisi olarak ele alınır. Yazılı metindeki tüm semboller bilinse de, ses kayıtları fonemlerin kendisini değil, fonemlerin dışavurumunu içerir (örneğin, 'R' sesini telaffuz etmenin birkaç yolu vardır).
Cihaz hangi fonemin telaffuz edildiğini bilmez; sadece belirli bir zamandaki ses dalgasının parametrelerini algılar. Sistem, belirli bir fonemin ortaya çıkma olasılığını tahmin etmenin yanı sıra, fonemleri uygun sinyal varyantlarıyla ilişkilendirmek zorundadır.
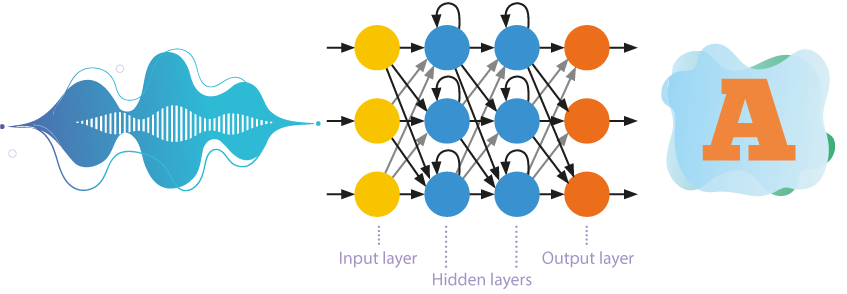
İleri beslemeli sinir ağları
Yakın zamana kadar, çok sayıda katmana sahip kendi kendine öğrenen sinir ağları en çok konuşma tanımada kullanılıyordu.
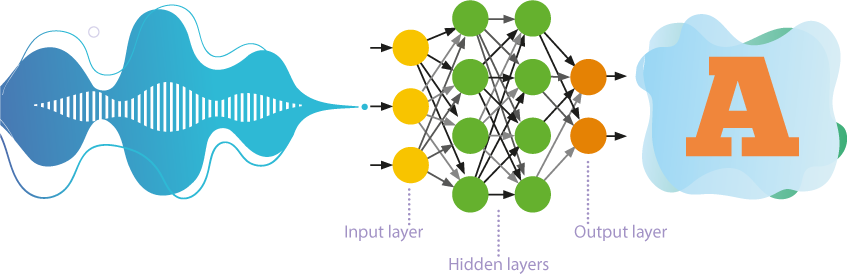
- Bu ağlar bilgiyi yalnızca bir yönde, yani giriş nöronlarından çıkış nöronlarına doğru işler.
- Giriş ve çıkış arasında hiyerarşik olarak birkaç nöron katmanı bulunur; burada daha yüksek düzeydeki parametreler, daha düşük düzeydeki parametrelerden kaynaklanır.
- Kendi kendine öğrenme veya denetimsiz öğrenme, sinir ağının dışarıdan müdahale olmadan sorunları çözmeyi öğrendiği anlamına gelir. Yaklaşım, eğitim örneğinin nesneleri arasındaki gizli kalıpları ortaya çıkarır.
Belirli bir fonemin ortaya çıkma olasılıklarını temsil eden sonuç, Markov modelinin tahmini ile karşılaştırılır. Belirgin bir ses oldukça doğru bir şekilde belirlenir.
Tekrarlayan sinir ağları
Konuşma tanıma sistemleri, basitleştirilmiş gizli Markov modellerinin kullanımından giderek uzaklaşmaktadır. Daha verimli tanıma için dahili hafıza ve geri yayılımın kullanıldığı tekrarlayan sinir ağları üzerine akustik modeller giderek daha fazla inşa edilmektedir.
Nöronlar sadece bir önceki katmandan bilgi almakla kalmaz, aynı zamanda kendi işlemlerinin sonuçlarını da kendilerine gönderir. Bu, verilerin oluşum sırasını dikkate almayı mümkün kılar.
4. İfade etme
İfadeleri ve cümleleri ayırt etme ilkesi, kelime kod çözme işlemine çok benzer. Daha önce, bu görev için N-gram tipi modeller kullanılıyordu; burada N önceki kelimeye (genellikle N = 3) bağlı olarak bir kelimenin ortaya çıkma olasılığı, büyük metin bloklarının analizine dayalı olarak belirleniyordu. |  |
Derin öğrenme ve tekrarlayan sinir ağlarının geliştirilmesi, dilsel modeli önemli ölçüde geliştirdi ve söylenenlerin bağlamını dikkate almasına izin verdi. Yalnızca N önceki kelimenin kullanımına ilişkin kısıtlama da ortadan kalktı.
Dilsel modeller artık çeşitli nedenlerden dolayı kaçırılan veya tanınmayan kelimeleri tahmin edebiliyordu. Bunun, yalnızca önceki kelimelerin değil tüm ifadenin önemli olduğu Rusça gibi rastgele kelime sırasına sahip diller için özellikle önemli olduğu ortaya çıktı.
Çoğu konuşma tanıma sistemi bu şekilde çalışır. Ancak söylenenleri anlamak yeterli değildir. Sistemin faydalı olması için gelen komutlara da yanıt verebilmesi gerekir: soruları yanıtlaması, uygulamaları açması ve diğer işlevleri yönetmesi gerekir. Bu görevlerden sesli asistanlar sorumludur.
MAG425A'da konuşma tanıma
 | MAG425A, sesle kontrol edilen bir uzaktan kumanda ve Google Asistan ile donatılmıştır. Sesli arayüz tamamen yeni bir kullanıcı deneyimi sağlar. Sesli asistanın gerçekleştirdiği ana işlevler şunlardır:
|
Google Asistan nedir?
Google Asistan, ilk olarak Kaliforniya'daki Google I/O 2016 konferansında tanıtılan sanal bir ses asistanıdır. Apple'ın Siri'si, Amazon'un Alexa'sı ve Microsoft'un Cortana'sı gibi, uygulama kullanıcının isteği üzerine bağlamsal bilgiler sağlar ve belirli eylemleri (arama sorguları girme, hatırlatıcı ayarlama, uygulamaları açma ve oynatmayı kontrol etme gibi) gerçekleştirebilir.
Google Asistan, bilgisayar destekli öğrenme ve Doğal Dil İşleme (NLP) teknolojisini kullanır. Sistem konuşmadaki sesleri, kelimeleri ve fikirleri ayırt edebilir.
Asistan bir milyar cihaz kullanmakta ve otuzdan fazla dili desteklemektedir, ancak Android TV sürümü şu ana kadar yalnızca on iki dili konuşmaktadır: İngilizce, Fransızca, Almanca, Hintçe, Endonezyaca, İtalyanca, Japonca, Korece, Portekizce, İspanyolca, İsveççe ve Vietnamca.

Google Asistan nasıl çalışır?
İlk olarak, uygulama tespit ettiği konuşmayı kaydeder. Konuşmayı yorumlamak kapsamlı hesaplama gücü gerektirir, bu nedenle Google Asistan, istekleri Google veri merkezlerine gönderir. Ses verileri bu merkezlerden birine ulaştığında, katı sinyal seslere bölünür. Google Asistan'ın algoritması, bir konuşma sesleri veritabanını arar ve kaydedilen ses kombinasyonu için hangi kelimelerin en iyi eşleştiğini belirler.
Sistem daha sonra kullanıcının ifadesinden ‘ana’ kelimeleri seçer ve nasıl yanıt vereceğine karar verir. Örneğin, Google Asistan ‘hava durumu‘ ve ‘bugün’ gibi kelimeleri fark ederse, bugünün hava durumu tahminiyle yanıt verecektir.
 | Google sunucuları bilgileri cihaza geri gönderir ve Google Asistan uygulaması istenen eylemi gerçekleştirir veya bir sesle yanıt verir. |
Google, Google Asistan'ın çalışma şeklini değiştirerek konuşmanın tanınmasını ve komutların doğrudan kullanıcının cihazında işlenmesini sağlar. Tekrarlayan sinir ağlarının yeteneklerini kullanan şirket, konuşma tanıma ve anlama için yeni bir model geliştirmiştir. Akustik model veritabanının boyutu yüz kat küçültüldü, böylece Asistan'ın yapay zekası halihazırda yerel olarak çalışabilmektedir. Uygulama, İnternet erişimi olmasa bile konuşmayı gerçek zamanlı olarak ve neredeyse sıfır gecikmeyle işler. |  |
Yeni nesil Google Asistan, isteklere neredeyse on kat daha hızlı yanıt vermektedir. 2019'dan bu yana Google'ın yeni Pixel akıllı telefon modelleri Google Asistan'ı destekliyor. Gelecekte, uygulama diğer cihazlarda da kullanılabilecek.
Bugün, Android TV'nin sesli arayüzü sadece milyon dolarlık bütçeye sahip şirketler için değil, aynı zamanda yerel IPTV/OTT operatörleri için de mevcuttur. Bu, operatörlerin yeni kitleleri çekmeleri, içerik aramaları oluşturmaları ve kullanıcılara daha kolay ve daha uygun hizmetlere erişmeleri için harika bir fırsattır; böylece rakiplerine karşı öne çıkabilirler.
*Google ve Android TV, Google LLC'nin ticari markalarıdır.
Recommended

IPTV'de Yapay Zeka: Kişiselleştirme ve Kullanıcı Deneyiminin Geliştirilmesi

Paket Teklifleri ve IPTV Abonelikleri: Farklı Kitlelere Hangi Tarifeleri Sunmalısınız?
Giderek daha rekabetçi hale gelen IPTV pazarında, iyi yapılandırılmış ve cazip fiyatlandırma planları oluşturmak, abone çekmek ve aboneleri elde tutmak için kritik öneme sahiptir. IPTV operatörleri, fiyatlandırma modellerini ve hizmet paketlerini farklı hedef kitlelerine uyarlamalı, esneklik, erişilebilirlik ve müşteri memnuniyetini sağlamalıdır. Bu makalede, farklı abonelik modellerini, bunların avantajlarını ve IPTV tarifelerini en iyi şekilde tasarlayarak gelirleri ve kullanıcı memnuniyetini nasıl maksimize edebileceğinizi inceleyeceğiz.

IPTV’de Oyunlaştırma: İzleyicileri Nasıl Çekebilir ve Elde Tutabilirsiniz?
Etkileşimli televizyonun (IPTV) gelişimi, hizmet sağlayıcılarının müşteri çekme ve elde tutma yöntemlerini kökten değiştirmiştir. Over-the-Top (OTT) hizmetleri, geleneksel kablolu TV ve diğer dijital platformlarla rekabet eden operatörler, değişen tüketim alışkanlıkları, rekabetçi fiyatlandırma ve içerik fazlalığı nedeniyle abonelerin dikkatini çekmek ve korumak için giderek artan zorluklarla karşı karşıya kalmaktadır. Bu soruna en etkili çözümlerden biri, oyun tasarım öğelerinin ve ilkelerinin oyun dışı bağlamlara entegre edilmesi olan oyunlaştırmadır. IPTV platformuna oyunlaştırmayı entegre ederek, operatörler kullanıcı etkileşimini artırabilir, marka sadakatini güçlendirebilir ve son derece rekabetçi bir pazarda kendilerini farklılaştırabilirler. Bu makale, IPTV hizmetlerinde oyunlaştırmanın potansiyelini keşfedecek, stratejilerini ve avantajlarını analiz edecek ve uygulanması için öneriler sunacaktır.
