





Proposta comercial
Selecione o objetivo do pedido:
Product request
You are looking for a solution:
Select an option, and we will develop the best offer
for you


Seu Desejo É Uma Ordem

 | Trinta e um anos atrás, uma TV que respondia a comandos de voz no filme De Volta para o Futuro, Parte II era uma ideia tão fantástica quanto um carro voador. Hoje, quase todos têm acesso a dispositivos com interfaces de voz. Neste artigo, vamos explicar como o reconhecimento de fala funciona e mostrar como os assistentes de voz operam, usando o Google Assistant como exemplo. |
Primeiros experimentos em reconhecimento de voz
 | Surpreendentemente, o primeiro produto doméstico com uma interface de voz (VI) foi um brinquedo. Em 1987, a boneca Julie, que podia ser treinada para reconhecer a fala das crianças, foi lançada. Julie reagia a estímulos como apagar a luz e lia em voz alta os livros que a acompanhavam. |
Alguns anos depois, o primeiro software de ditado com reconhecimento de voz apareceu, além de dispositivos para deficientes visuais e pessoas que não podiam usar teclados de computador devido a limitações físicas.
Em 1990, uma licença do DragonDictate, a primeira "máquina de escrever por voz", custava $9000.
Later in the Mais tarde, na década de 1990, outras interfaces de voz foram introduzidas para automatizar processos de negócios. Por exemplo, o portal VAL da BellSouth processava consultas telefônicas e informava aos clientes sobre os serviços da empresa. Infelizmente, essas soluções iniciais eram imprecisas e exigiam treinamento prolongado.
| A tecnologia melhorou constantemente ao longo do tempo e hoje muitos dos dispositivos "inteligentes" disponíveis para os consumidores vêm equipados com interfaces de voz. Os fabricantes de produtos tecnológicos incorporaram o reconhecimento de voz em seus dispositivos para oferecer aos clientes maior facilidade de uso e operação sem as mãos. Falar é mais fácil do que digitar quando você está no meio das atividades diárias - enquanto está dirigindo ou se locomovendo, ou quando está em frente à sua TV. |

Os sistemas de reconhecimento de fala atuais nos ajudam a encontrar informações, transcrever texto e agendar compromissos. Eles são usados em sistemas interativos de autoatendimento, por exemplo, serviços de suporte técnico.
Como funciona o reconhecimento de fala?
Os dispositivos percebem a fala de maneira diferente dos humanos. Em vez de palavras isoladas, um dispositivo ouve um sinal contínuo, no qual os sons fluem suavemente uns para os outros. Um dispositivo detectará uma única frase pronunciada com diferentes entonações ou por diferentes falantes como sinais distintos. Devido ao alto grau de variabilidade na fala humana, a precisão do reconhecimento de voz ainda não alcançou 100%. A principal tarefa dos algoritmos de reconhecimento de voz é interpretar o que foi dito, independentemente das peculiaridades de pronúncia do falante ou da presença de ruído de fundo e outras interferências. |  |
Elementos de um sistema de reconhecimento de fala
Sistemas de reconhecimento de fala consistem em quatro componentes:
- um módulo de limpeza de som (para remover ruídos de fundo)
- um modelo acústico (para discernir os sons da fala)
- um padrão de linguagem (para prever as sequências de palavras mais prováveis)
- um decodificador (para combinar os dados de saída do modelo acústico com o padrão de linguagem e fornecer o resultado final)
Em cada estágio, o sinal acústico passa por uma série de transformações. Você pode ler mais sobre esses abaixo.
1. Limpeza de som
A primeira tarefa de um sistema de reconhecimento de fala é avaliar a qualidade do sinal de entrada de áudio e separar o sinal desejado das interferências sonoras, ou ruído. Dependendo da natureza do som indesejado, diferentes abordagens podem ser usadas para filtrar a fala do ruído de fundo.
Supressão de ruído
Existem várias maneiras de suprimir ruídos em um sistema de reconhecimento de fala. Uma delas é introduzir ruído artificial, incluindo gravações de ruídos comuns feitos pelo homem (por exemplo, o som de um motor de carro, vento ou chuva), no sistema para 'ensinar' o modelo acústico a distinguir som de ruído de fundo. No entanto, quando o sistema encontrar ruídos desconhecidos, o modelo provavelmente enviará uma mensagem de 'erro'.
Outras abordagens de supressão de ruído dependem de soluções de hardware. Alguns smartphones são equipados com dois microfones: o primeiro microfone, localizado na parte frontal do dispositivo, capta a fala com interferência, enquanto um segundo microfone na parte traseira capta o ruído ambiente de fundo. Em teoria, tudo o que você precisa fazer para obter um sinal claro é simplesmente subtrair o segundo sinal sonoro do primeiro.
Vozes estranhas
É mais difícil isolar uma voz específica quando várias pessoas estão falando ao mesmo tempo do que distinguir fala de sons não verbais. Para isolar um orador individual de outras vozes, o modelo acústico se adapta à voz do usuário e memoriza as peculiaridades de sua pronúncia.
2. Dividindo um sinal de fala em palavras
A próxima tarefa para um sistema de reconhecimento de voz é isolar palavras individuais em um fluxo sonoro contínuo e determinar seu significado.
Em seu nível mais básico, a fala pode ser vista como alternância entre sons e silêncios. Os silêncios podem ser entendidos como "separadores" de palavras.
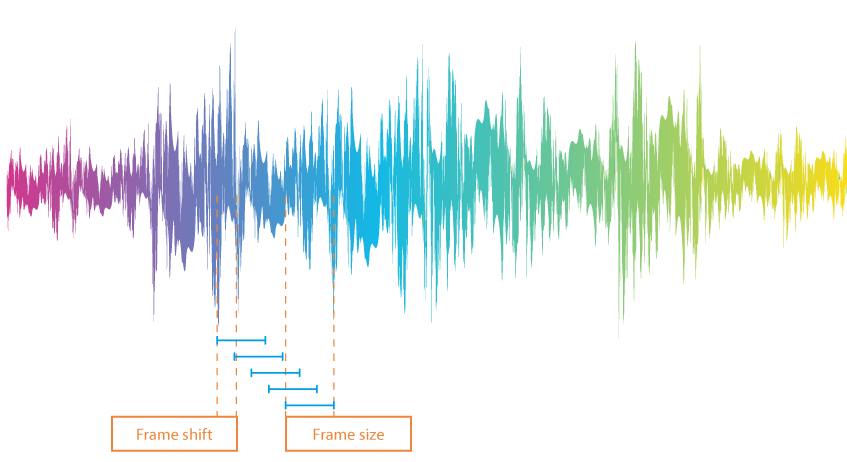
Para analisar um sinal de fala em termos de palavras e separadores de palavras, uma gravação de áudio é primeiro dividida em quadros, ou seja, pequenas seções com aproximadamente 10 ms de duração. Esses quadros não são estritamente consecutivos: o final de uma seção é sobreposto ao início de outra.
Para determinar quais dos quadros contêm vozes humanas, o sistema estabelece um limite. Valores acima do limite são considerados palavras, enquanto valores abaixo são entendidos como silêncio. Há várias opções para definir o valor limite:
- Definindo-o como uma constante (essa constante pode ser usada quando o som é gerado da mesma forma e sob as mesmas condições).
- Definindo um número de valores que correspondem ao silêncio (se o silêncio ocupar uma parte significativa da gravação).
- Realizando uma análise de entropia (isso requer determinar o quão fortemente o sinal 'oscila' dentro de um determinado quadro). A amplitude das oscilações para partes silenciosas de uma gravação geralmente é mais baixa.
Das três opções, a análise de entropia é considerada a mais confiável, embora tenha suas falhas. Por exemplo, a entropia pode diminuir quando vogais são prolongadas ou aumentar com um leve ruído. Para resolver o problema, são introduzidos dois conceitos: "distância mínima entre palavras" e "comprimento mínimo de palavra". O algoritmo mescla fragmentos que são muito curtos e elimina o ruído.
3. Interpretação de palavras
 | Na maioria das vezes, redes neurais, combinadas com um aparato contendo modelos ocultos de Markov, são usadas para interpretar palavras. |
Modelos Markov ocultos Ao pesquisar textos literários do início do século XX, o matemático Andrey Markov inicialmente assumiu que a probabilidade da ocorrência de uma letra dependia da letra que a precedia. Descobriu-se que esse valor permanecia constante em diferentes partes do mesmo texto. | 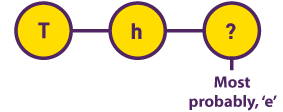 |
Os indicadores de probabilidade são únicos para cada autor. Isso torna possível usar modelos de Markov para detectar plágio.
Nos modelos de Markov, o texto impresso consiste em sequências de caracteres, enquanto a fala é tratada como uma sequência de fonemas. Enquanto todos os símbolos no texto escrito são conhecidos, as gravações de voz contêm a manifestação dos fonemas e não os fonemas em si (por exemplo, há várias maneiras de pronunciar o som 'R').
O dispositivo não sabe qual fonema foi pronunciado; ele percebe apenas os parâmetros da onda sonora em um determinado momento no tempo. Além de estimar a probabilidade da ocorrência de um fonema específico, o sistema precisa associar os fonemas com as variantes adequadas do sinal sonoro.
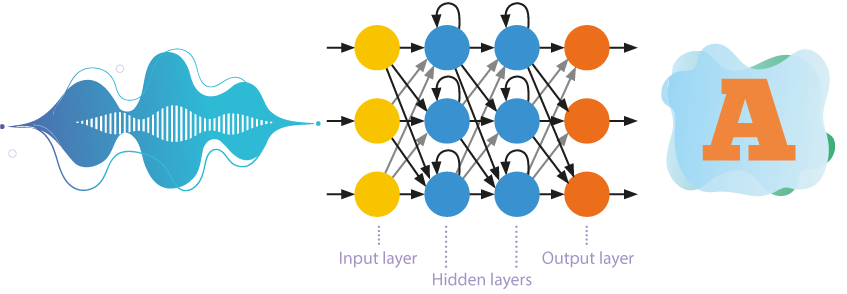
Redes neurais feedforward
Até recentemente, redes neurais com auto-aprendizagem com numerosas camadas eram mais frequentemente usadas no reconhecimento de fala.
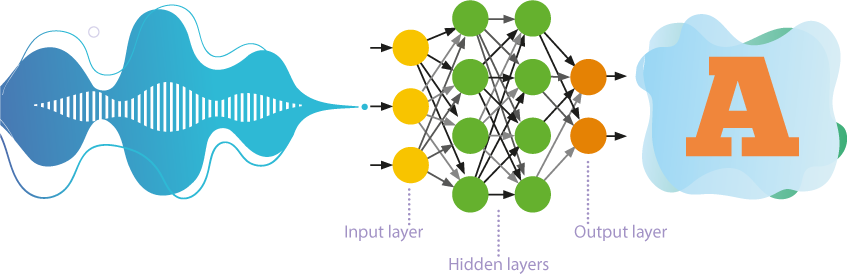
- Essas redes processam informações em apenas uma direção, ou seja, dos neurônios de entrada para os neurônios de saída.
- Várias camadas de neurônios são hierarquicamente localizadas entre a entrada e a saída, onde os parâmetros de um nível superior derivam dos parâmetros de um nível inferior.
- A aprendizagem auto-supervisionada ou não supervisionada implica que a rede neural aprende a resolver problemas sem intervenção externa. Essa abordagem revela padrões ocultos entre os objetos da amostra de treinamento.
O resultado, que representa um conjunto de probabilidades da ocorrência de um fonema específico, é comparado com a previsão do modelo de Markov. Um som pronunciado é determinado com bastante precisão.
Redes neurais recorrentes
Os sistemas de reconhecimento de fala estão gradualmente abandonando o uso de modelos ocultos de Markov simplificados. Cada vez mais, modelos acústicos estão sendo construídos com redes neurais recorrentes, onde a memória interna e a retropropagação são utilizadas para um reconhecimento mais eficiente.
Os neurônios não apenas recebem informações da camada anterior, mas também enviam os resultados de seu próprio processamento para si mesmos. Isso permite considerar a ordem de ocorrência dos dados.
4. Formulação
O princípio de distinguir frases e sentenças é muito semelhante ao decodificar palavras. Anteriormente, modelos do tipo N-grama eram usados para essa tarefa, onde a probabilidade de ocorrência de uma palavra dependendo das N palavras anteriores (geralmente N = 3) era determinada com base na análise de grandes blocos de texto |  |
A aprendizagem profunda e o desenvolvimento de redes neurais recorrentes melhoraram significativamente o modelo linguístico e permitiram que ele levasse em conta o contexto do que foi dito. A restrição de usar apenas as N palavras anteriores também desapareceu.
Os modelos linguísticos agora eram capazes de adivinhar as palavras perdidas ou não reconhecidas por diversos motivos. Isso acabou sendo especialmente importante para idiomas com ordem de palavras aleatória, como o russo, onde não apenas as palavras anteriores eram importantes, mas toda a frase.
Assim é como a maioria dos sistemas de reconhecimento de fala funcionam. Mas não é suficiente para entender o que foi dito. Para ser útil, o sistema também precisa ser capaz de responder a comandos recebidos: ele precisa responder perguntas, abrir aplicativos e gerenciar outras funções. Assistentes de voz são responsáveis por essas tarefas.
O reconhecimento de fala na MAG425A
 | A MAG425A é equipado com um controle remoto controlado por voz e o Google Assistant. A interface de voz proporciona uma experiência completamente nova para o usuário. As principais funções que o assistente de voz realiza incluem
|
O que é o Google Assistant?
O Google Assistant é um assistente virtual de voz introduzido pela primeira vez na conferência Google I/O 2016 na Califórnia. Assim como a Siri da Apple, a Alexa da Amazon e a Cortana da Microsoft, o aplicativo fornece informações contextuais conforme solicitado pelo usuário e é capaz de realizar certas ações (como fazer buscas, definir lembretes, abrir aplicativos e controlar reprodução).
O Google Assistant utiliza aprendizado assistido por computador e tecnologia de Processamento de Linguagem Natural (NLP). O sistema é capaz de identificar sons, palavras e ideias na fala.
O Assistant opera em bilhões de dispositivos e suporta mais de trinta idiomas, mas a versão para Android TV atualmente só fala doze idiomas: inglês, francês, alemão, hindi, indonésio, italiano, japonês, coreano, português, espanhol, sueco e vietnamita.

Como o Google Assistant funciona?
Primeiro, o aplicativo grava a fala que detecta. Interpretar fala requer poder computacional extenso, então o Google Assistant envia pedidos aos centros de dados do Google. Quando os dados de som alcançam um desses centros, o sinal sólido é dividido em sons. O algoritmo do Google Assistant busca uma base de dados de sons de fala e determina quais palavras mais se assemelham à combinação gravada de sons.
O sistema então seleciona as palavras 'principais' da fala do usuário e decide como responder. Por exemplo, se o Google Assistant perceber palavras como 'clima' e 'hoje', ele responderá com a previsão do clima para hoje.
 | Os servidores do Google enviam as informações de volta ao dispositivo, e então o aplicativo do Google Assistant executa a ação desejada ou responde com uma voz. |
O Google está mudando a maneira como o Google Assistant funciona para que a fala seja reconhecida e os comandos sejam processados diretamente no dispositivo do usuário. Usando as capacidades de redes neurais recorrentes, a companhia desenvolveu um novo modelo para o reconhecimento e compreensão de fala. O tamanho da base de dados de modelos acústicos passou por uma redução em cem vezes, para que a inteligência artificial do Assistant possa trabalhar localmente. O aplicativo processa a fala em tempo real e com atraso quase zero, mesmo sem acesso à Internet. |  |
Um Google Assistant de nova geração responde a pedidos quase dez vezes mais rápido. Desde 2019, os modelos novos de smartphone Google Pixel têm suporte para o Google Assistant. No futuro, o aplicativo estará disponível em outros dispositivos também.
Hoje, a interface de voz da Android TV está disponível não somente para empresas com orçamentos de milhões de dólares, mas também operadoras locais de IPTV/OTT. Esta é uma grande oportunidade para as operadoras atraírem novos públicos, criarem buscas de conteúdo e tornar o acesso a serviços mais conveniente para os usuários, para que possam se destacar em relação à concorrência.
*Google e Android TV são marcas registradas da Google LLC.
Recommended

Como melhorar a retenção de espectadores com notificações push inteligentes
No mercado de IPTV atual, a concorrência pela atenção do espectador tornou-se tão intensa quanto a disputa por conteúdo

Como construir corretamente um ambiente de staging para testar atualizações de IPTV
Qualquer atualização em um ecossistema de IPTV afeta mais de um componente e pode impactar autenticação, reprodução, EPG, VoD, DRM e a estabilidade da rede.

Nichos B2B para IPTV: de hotéis à TV corporativa
O IPTV está cada vez mais indo além dos limites do negócio clássico de operadoras e da TV para consumidores. Para o segmento B2B – de hotéis e centros empresariais a instituições médicas e escritórios corporativos – o IPTV está se tornando uma ferramenta de serviço, comunicação e gestão de atenção.
