





Product request
You are looking for a solution:
Select an option, and we will develop the best offer
for you


Ogni tuo desiderio è un ordine

 | Trentuno anni fa, una TV che rispondeva ai comandi vocali nel film Ritorno al futuro, parte II era un'idea fantastica come un'auto volante, quasi tutti hanno accesso a dispositivi con interfacce vocali. In questo articolo, spiegheremo come funziona il riconoscimento vocale e ti mostreremo come funzionano gli assistenti vocali, utilizzando l' Assistente Google come esempio. |
Primi esperimenti nel riconoscimento vocale
 | Sorprendentemente, il primo prodotto per la casa con un'interfaccia vocale (VI) era un giocattolo. Nel 1987 fu lanciata la bambola Julie, che poteva essere addestrata a riconoscere il linguaggio dei bambini. Julie reagiva a stimoli come spegnere la luce e leggere ad alta voce i libri. |
Pochi anni dopo apparve il primo software di dettatura del riconoscimento vocale, oltre a dispositivi per ipovedenti e persone che non potevano usare le tastiere del computer a causa di limitazioni fisiche.
Nel 1990, una licenza per DragonDictate, la prima "macchina da scrivere vocale", costava $9000.
Più tardi , negli anni '90, sono state introdotte altre interfacce vocali per automatizzare i processi aziendali. Ad esempio, il portale VAL di BellSouth ha elaborato le richieste telefoniche e ha informato i clienti sui servizi dell'azienda. Sfortunatamente, queste prime soluzioni erano imprecise e richiedevano una lunga formazione.
| La tecnologia è migliorata costantemente nel tempo e oggi molti dei dispositivi “intelligenti” a disposizione dei consumatori sono dotati di interfacce vocali. I produttori di prodotti tecnologici hanno integrato il riconoscimento vocale nei loro dispositivi per offrire ai clienti una maggiore facilità d'uso e un utilizzo a mani libere. Parlare è più facile che digitare quando si è nel bel mezzo delle attività quotidiane: mentre si guida o si è in viaggio, o quando si è davanti alla TV. |

I sistemi di riconoscimento vocale attuali ci aiutano a trovare informazioni, trascrivere testo e fissare appuntamenti. Sono utilizzati in sistemi self-service interattivi, ad esempio servizi di supporto tecnico.
Come funziona il riconoscimento vocale?
I dispositivi percepiscono il parlato in modo diverso rispetto agli esseri umani. Invece di parole isolate, un dispositivo sente un segnale continuo, in cui i suoni fluiscono senza intoppi l'uno nell'altro. Un dispositivo rileverà una singola frase pronunciata con intonazioni diverse o espressa da diversi altoparlanti come segnali diversi. A causa dell'elevato grado di variabilità del linguaggio umano, la precisione del riconoscimento vocale non ha ancora raggiunto il 100%. Il compito principale degli algoritmi di riconoscimento vocale è quello di interpretare ciò che è stato detto indipendentemente dalle peculiarità di pronuncia del parlante o dalla presenza di rumore di fondo e altre interferenze. |  |
Elementi di un sistema di riconoscimento vocale
I sistemi di riconoscimento vocale sono costituiti da quattro componenti:
- un modulo di pulizia del suono (per rimuovere il rumore di fondo)
- un modello acustico (per discernere i suoni del discorso)
- un modello linguistico (per prevedere le sequenze di parole più probabili)
- un decodificatore (per combinare i dati in uscita dal modello acustico con il modello del linguaggio per fornire il risultato finale)
Ad ogni stadio, il segnale acustico subisce una serie di trasformazioni. Puoi saperne di più qui sotto.
1. Pulizia del suono
Il primo compito di un sistema di riconoscimento vocale è valutare la qualità dell'input sonoro e separare il segnale desiderato dalle interferenze sonore o dal rumore. A seconda della natura del suono indesiderato, è possibile utilizzare approcci diversi per filtrare il parlato dal rumore di fondo.
Eliminazione del rumore
Esistono diversi modi per sopprimere il rumore in un sistema di riconoscimento vocale. Uno di questi è quello di introdurre il rumore artificiale, comprese le registrazioni di rumori comuni prodotti dall'uomo (ad esempio, il suono del motore di un'auto, il vento o la pioggia), nel sistema per "insegnare" al modello acustico a distinguere il suono dal rumore di fondo. Tuttavia, quando in seguito il sistema rileva un rumore sconosciuto, il modello probabilmente invierà un messaggio di "errore".
Altri approcci di soppressione del rumore si basano su soluzioni hardware. Alcuni smartphone sono dotati di due microfoni: il primo microfono, situato sulla parte anteriore del dispositivo, cattura il parlato con interferenza mentre un secondo microfono sul retro rileva il rumore di fondo ambientale. In teoria, tutto ciò che devi fare per ottenere un segnale chiaro è semplicemente sottrarre il secondo segnale sonoro dal primo.
Voci estranee
È più difficile distinguere una voce particolare quando più persone parlano contemporaneamente piuttosto che distinguere il parlato dai suoni non vocali. Per isolare un singolo interlocutore dalle altre voci, il modello acustico si adatta alla voce dell'utente e ricorda le peculiarità della sua pronuncia.
2. Dividere un segnale vocale in parole
Il compito successivo per un sistema di riconoscimento vocale è quello di individuare le singole parole in un flusso sonoro continuo e determinarne il significato.
Al suo livello più elementare, il discorso può essere visto come alternanza di suoni e silenzi. I silenzi possono essere intesi come "separatori" di parole.
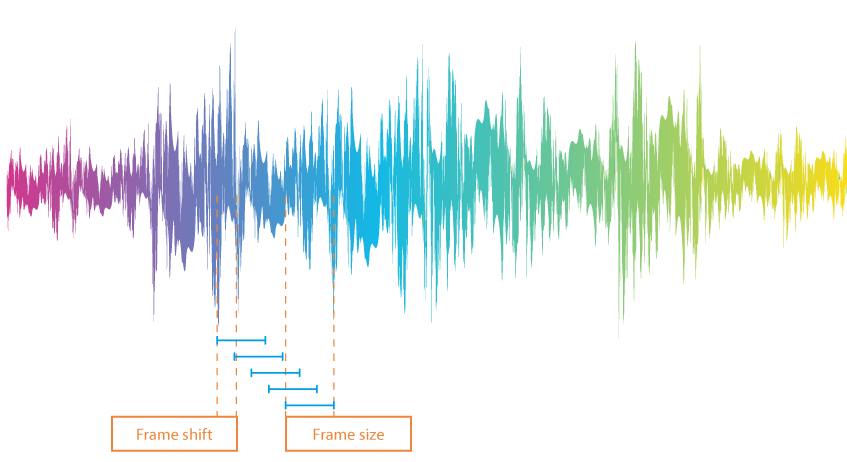
Per analizzare un segnale vocale in termini di parole e separatori di parole, una registrazione audio viene prima suddivisa in frame, ovvero piccole sezioni di circa 10 ms di lunghezza. Questi spezzoni non sono strettamente consecutivi: la fine di una sezione è sovrapposta all'inizio di un'altra.
Per determinare quali spezzoni contengono voci umane, il sistema imposta un limite. I valori al di sopra del limite sono considerati parole, mentre i valori al di sotto sono intesi come silenzio. Esistono diverse opzioni per impostare il valore limite:
- Impostandola come costante (questa costante può essere utilizzata quando il suono viene generato nello stesso modo e nelle stesse condizioni).
- Definire un numero di valori che corrispondono al silenzio (se il silenzio occupa una parte significativa della registrazione).
- Esecuzione di un'analisi entropica (ciò richiede la determinazione della forza con cui il segnale "oscilla" all'interno di un determinato spezzone. L'ampiezza delle oscillazioni per le parti silenziose di una registrazione è solitamente inferiore).
Dei tre, l'analisi entropica è considerata la più affidabile, sebbene abbia i suoi difetti. Ad esempio, l'entropia può diminuire quando le vocali sono tratteggiate o aumentare con un leggero rumore. Per risolvere il problema, vengono introdotti due concetti: una "distanza minima tra le parole" e una "lunghezza minima delle parole". L'algoritmo unisce frammenti troppo corti e interrompe il rumore.
3. Interpretazione delle parole
 | Molto spesso, le reti neurali, combinate con un apparato contenente modelli di Markov nascosti, vengono utilizzate per interpretare le parole. |
Modelli Markov nascosti Durante la ricerca di testi letterari dell'inizio del XX secolo, il matematico Andrey Markov inizialmente ipotizzò che la probabilità del verificarsi di una lettera dipendesse dalla lettera che la precedeva. Si è scoperto che questo valore rimaneva costante in diverse parti dello stesso testo. | 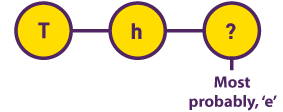 |
Gli indicatori di probabilità sono unici per ogni autore. Ciò consente di utilizzare i modelli Markov per individuare il plagio.
Nei modelli di Markov, il testo stampato è costituito da sequenze di caratteri mentre il discorso è trattato come una sequenza di fonemi. Mentre tutti i simboli nel testo scritto sono noti, le registrazioni vocali contengono la manifestazione dei fonemi e non i fonemi stessi (ad esempio, ci sono diversi modi per pronunciare il suono "R").
Il dispositivo non sa quale fonema è stato pronunciato; percepisce solo i parametri dell'onda sonora in un determinato momento nel tempo. Oltre a stimare la probabilità del verificarsi di un particolare fonema, il sistema deve associare i fonemi a varianti di segnale appropriate.
Reti neurali feedforward
Fino a poco tempo fa, le reti neurali ad autoapprendimento con numerosi livelli erano più spesso utilizzate nel riconoscimento vocale.
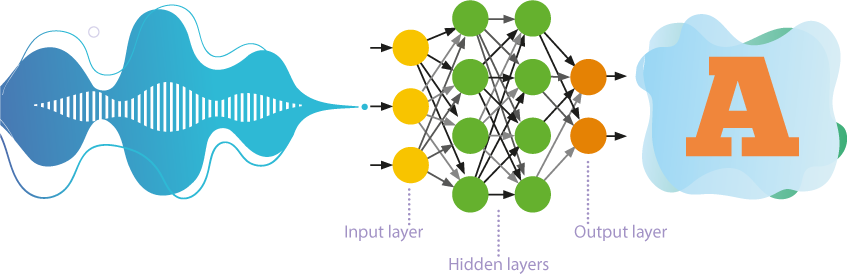
- Queste reti elaborano le informazioni in una sola direzione, vale a dire dai neuroni di input ai neuroni di output.
- Diversi strati di neuroni sono posizionati gerarchicamente tra l'ingresso e l'uscita, dove i parametri di un livello superiore derivano dai parametri di un livello inferiore.
- L'approccio rivela schemi nascosti tra gli oggetti del campione di allenamento.
Il risultato, che rappresenta un insieme di probabilità del verificarsi di un particolare fonema, viene confrontato con la previsione del modello di Markov. Un suono pronunciato è determinato in modo abbastanza accurato.
Recurrent neural networks
I sistemi di riconoscimento vocale si stanno gradualmente allontanando dall'uso di modelli di Markov nascosti semplificati. Sempre più spesso, i modelli acustici vengono costruiti su reti neurali ricorrenti, in cui la memoria interna e la backpropagation vengono utilizzate per un riconoscimento più efficiente.
I neuroni non solo ricevono informazioni dallo strato precedente, ma inviano anche a se stessi i risultati della propria elaborazione. Ciò consente di considerare l'ordine di occorrenza dei dati.
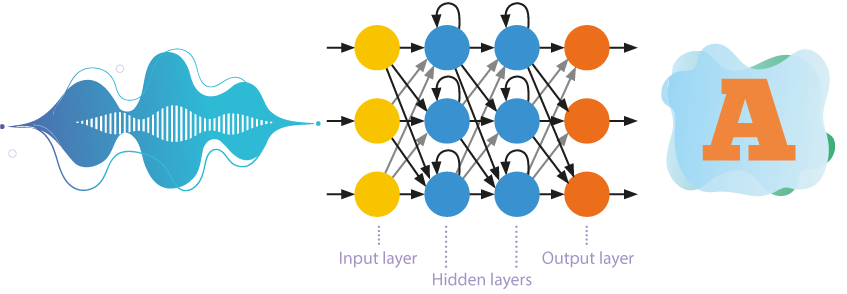
4. Phrasing
Il principio di distinguere espressioni e frasi è molto simile alla decodifica delle parole. In precedenza, per questo compito venivano utilizzati modelli di tipo N-grammo, in cui la probabilità di occorrenza di una parola dipendeva da N parole precedenti (usu. N = 3) è stato determinato sulla base dell'analisi di grandi blocchi di testo. | 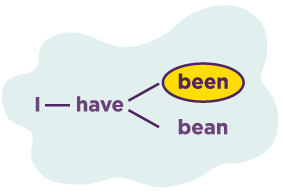 |
Il deep learning e lo sviluppo di reti neurali ricorrenti hanno migliorato significativamente il modello linguistico e gli hanno permesso di tenere conto del contesto di ciò che è stato detto. Scomparve anche la restrizione all'uso delle sole N parole precedenti.
I modelli linguistici erano ora in grado di indovinare le parole perse o non riconosciute per una serie di motivi. Questo si è rivelato particolarmente importante per le lingue con un ordine casuale di parole come il russo, dove non solo le parole precedenti erano importanti, ma l'intera frase.
È così che funziona la maggior parte dei sistemi di riconoscimento vocale. Ma non basta capire quello che è stato detto. Per essere utile, il sistema deve anche essere in grado di rispondere ai comandi in arrivo: deve rispondere a domande, aprire app e gestire altre funzioni. Gli assistenti vocali sono responsabili di queste attività.
Riconoscimento vocale in MAG425A
 | Il MAG425A è dotato di telecomando a comando vocale e Google Assistant. L'interfaccia vocale offre un'esperienza utente completamente nuova. Le principali funzioni svolte dall'assistente vocale includono:
|
Cos' è l'Assistente Google?
Google Assistant è un assistente vocale virtuale introdotto per la prima volta alla conferenza Google I/O 2016 in California. Come Siri di Apple, Alexa di Amazon e Cortana di Microsoft, l'applicazione fornisce informazioni contestuali su richiesta dell'utente ed è in grado di eseguire determinate azioni (come l'immissione di query di ricerca, l'impostazione di promemoria, l'apertura di applicazioni e il controllo della riproduzione).
Google Assistant utilizza l'apprendimento assistito da computer e la tecnologia Natural Language Processing (NLP). Il sistema è in grado di individuare suoni, parole e idee nel parlato.
L'Assistente gestisce un miliardo di dispositivi e supporta oltre trenta lingue, ma la versione Android TV finora parla solo dodici lingue: inglese, francese, tedesco, hindi, indonesiano, italiano, giapponese, coreano, portoghese, spagnolo, svedese e vietnamita.

Come funziona l'Assistente Google?
In primo luogo, l'applicazione registra il discorso che rileva. L'interpretazione del parlato richiede un'ampia potenza di calcolo, quindi l'Assistente Google invia le richieste ai data center di Google. Quando i dati sonori raggiungono uno di questi centri, il segnale solido è diviso in suoni. L'algoritmo dell'Assistente Google cerca in un database di suoni vocali e determina quali parole corrispondono meglio alla combinazione di suoni registrata.
Il sistema quindi individua le parole "principali" dalla dichiarazione dell'utente e decide come rispondere. Ad esempio, se l'Assistente Google nota parole come "meteo" e "oggi", risponderà con le previsioni meteorologiche di oggi.
 | I server di Google inviano le informazioni al dispositivo e l'app Google Assistant esegue l'azione desiderata o risponde con una voce. |
Google sta cambiando il modo in cui funziona l'Assistente Google in modo che la voce venga riconosciuta e i comandi vengano elaborati direttamente sul dispositivo dell'utente. Utilizzando le capacità delle reti neurali ricorrenti, l'azienda ha sviluppato un nuovo modello per il riconoscimento e la comprensione del parlato. La dimensione del database di modelli acustici ha subito una riduzione di cento volte, quindi l'intelligenza artificiale di Assistant può già funzionare localmente. L'applicazione elabora il parlato in tempo reale e con un ritardo quasi nullo, anche senza accesso a Internet. |  |
L'Assistente Google di nuova generazione risponde a una richiesta quasi dieci volte più velocemente. Dal 2019, i nuovi modelli di smartphone Pixel di Google supportano Google Assistant. In futuro, l'app sarà disponibile anche su altri dispositivi.
Oggi, l'interfaccia vocale di Android TV è disponibile non solo per le aziende con budget da milioni di dollari, ma anche per gli operatori IPTV/ott locali. Questa è una grande opportunità per gli operatori di attrarre nuovo pubblico, creare ricerche di contenuti e accedere ai servizi in modo più semplice e conveniente per gli utenti in modo che possano distinguersi dai loro concorrenti.
*Google e Android TV sono marchi di Google LLC.
Recommended

Come migliorare la fidelizzazione degli spettatori con notifiche push intelligenti
Nel mercato IPTV odierno, la competizione per l’attenzione degli spettatori è diventata intensa quanto la lotta per i contenuti.

Come costruire correttamente un ambiente di staging per testare gli aggiornamenti IPTV
Qualsiasi aggiornamento in un ecosistema IPTV influisce su più componenti e può impattare autenticazione, avvio dei canali, EPG, VoD, DRM e stabilità della rete.

Nicchie B2B per IPTV: dagli hotel alla TV aziendale
IPTV sta sempre più andando oltre i confini del classico business degli operatori e della TV per i consumatori. Per il segmento B2B – dagli hotel e centri business alle strutture mediche e agli uffici aziendali – IPTV sta diventando uno strumento di servizio, comunicazione e gestione dell’attenzione.
