





Product request
You are looking for a solution:
Select an option, and we will develop the best offer
for you


Sus deseos son órdenes

 | Hace 31 años, una TV que respondía a comandos de voz en la película Regreso al Futuro II era una idea tan fantástica como un coche volador - ahora, casi todo el mundo tiene acceso a dispositivos con interfaces de voz. En este artículo, te explicaremos cómo funciona el reconocimiento de voz y te mostraremos cómo funcionan los asistentes de voz, utilizando Google Assistant como ejemplo. |
Primeros experimentos de reconocimiento de voz
 | Sorprendentemente, el primer producto doméstico con interfaz de voz (VI) fue un juguete. En 1987 salió a la venta la muñeca "Julie", que podía entrenarse para reconocer el habla de los niños. Julie reaccionaba a estímulos como apagar la luz y leía en voz alta los libros que venían con ella. |
Pocos años después aparecieron los primeros programas para dictar con reconocimiento de voz, además de dispositivos para discapacitados visuales y personas que no podían utilizar teclados de ordenador por limitaciones físicas.
En 1990, una licencia de DragonDictate, la primera "máquina de escribir por voz", costaba 9.000 $.
Más adelante, en los años 90, se introdujeron otras interfaces de voz para automatizar procesos a nivel empresarial. Por ejemplo, el portal VAL de BellSouth procesaba las consultas telefónicas e informaba a los clientes sobre sus servicios. Por desgracia, estas primeras soluciones eran imprecisas y requerían una larga formación.
| La tecnología fue mejorando con el tiempo y, hoy en día, muchos de los dispositivos "inteligentes" a disposición de los consumidores vienen equipados con interfaces de voz. Los fabricantes de dispositivos tecnológicos han incorporado el reconocimiento de voz a sus aparatos para ofrecer a sus clientes una mayor facilidad de uso y un funcionamiento de manos libres. Hablar es más fácil que teclear cuando se está en medio de las actividades rutinarias: al conducir o ir al trabajo, o cuando se está delante de la TV. |

Los sistemas actuales de reconocimiento de voz facilitan la búsqueda de información, la transcripción de textos y la organización de citas. Se utilizan en sistemas interactivos de autoservicio como, por ejemplo, los servicios de asistencia técnica.
¿Cómo funciona el reconocimiento de voz?
Los dispositivos perciben el habla de forma distinta a los humanos. En lugar de palabras aisladas, un aparato oye una señal continua, en la que los sonidos fluyen entre sí. Un dispositivo detectará una misma frase pronunciada con distintas entonaciones o por distintos locutores como señales diferentes. Debido al alto grado de variabilidad del habla humana, la precisión del reconocimiento de voz todavía no ha alcanzado el 100%. La principal tarea de los algoritmos de reconocimiento de voz es interpretar lo que se ha dicho independientemente de las peculiaridades de pronunciación del hablante o de la presencia de ruido de fondo y otras interferencias. |  |
Elementos del sistema de reconocimiento de voz
Los sistemas de reconocimiento de voz constan de cuatro componentes:
- un módulo de limpieza acústica (para eliminar el ruido de fondo)
- un modelo acústico (para discernir los sonidos del habla)
- un patrón lingüístico (para predecir las secuencias de palabras más probables)
- un decodificador (para combinar los datos obtenidos del modelo acústico con el patrón lingüístico y obtener el resultado final)
En cada etapa, la señal acústica atraviesa una serie de transformaciones. A continuación se describen con más detalle.
1. Limpieza acústica
La primera tarea de un sistema de reconocimiento del habla es evaluar la calidad del sonido de entrada y separar la señal deseada de las interferencias sonoras, o del ruido. Dependiendo de la naturaleza del sonido no deseado, se pueden utilizar distintos enfoques para filtrar el habla del ruido de fondo.
Supresión del ruido
Hay varias formas de suprimir el ruido en un sistema de reconocimiento de voz. Un método consiste en introducir ruido artificial en el sistema (por ejemplo, el sonido del motor de un coche, el viento o la lluvia) para "enseñar" al modelo acústico a distinguir el sonido del ruido de fondo. Sin embargo, cuando el sistema se encuentra más tarde con un ruido desconocido, es probable que el modelo envíe un mensaje de "error".
Otros métodos de supresión del ruido se basan en soluciones de hardware. Algunos smartphones están equipados con dos micrófonos: el primero, situado en la parte delantera del dispositivo, capta el habla con interferencias, mientras que un segundo micrófono, en la parte trasera, recoge el ruido de fondo ambiental. En teoría, todo lo que hay que hacer para obtener una señal clara es sustraer la segunda señal sonora de la primera.
Voces extrañas
Resulta más complicado distinguir una voz concreta cuando varias personas hablan al mismo tiempo, que distinguir el habla de los sonidos no verbales. Para aislar a un orador individual de otras voces, el modelo acústico se adapta a la voz del usuario y recuerda las peculiaridades de su pronunciación.
2. Dividir una señal verbal en palabras
La siguiente tarea de un sistema de reconocimiento de voz es identificar palabras individuales en un flujo sonoro continuo y determinar su significado.
En su nivel más básico, el habla puede verse como una alternancia de sonidos y silencios. Los silencios pueden entenderse como "separadores" de palabras.
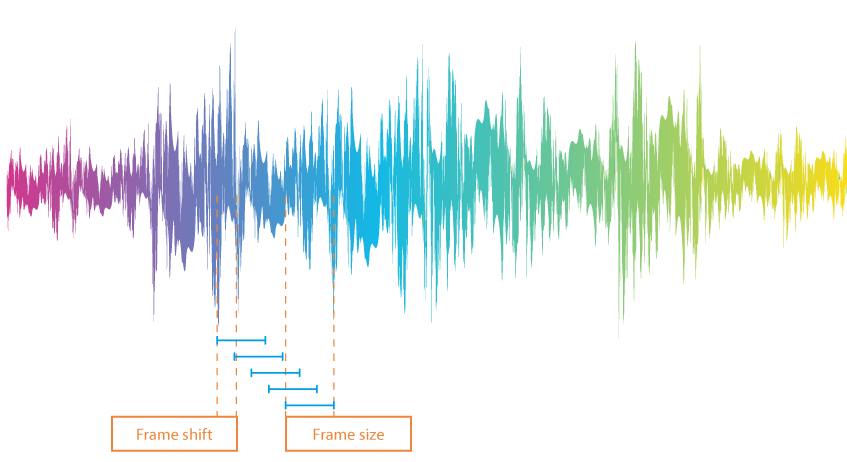
Para analizar una señal de voz en términos de palabras y separadores de palabras, primero se divide una grabación de sonido en fotogramas o tramos, es decir, pequeñas secciones de aproximadamente 10 ms de duración. Estos no deben ser estrictamente consecutivos: el final de una sección se superpone al principio de otra.
Para determinar cuáles de los tramos contienen voces humanas, el sistema establece un límite. Los valores por encima del límite se consideran palabras, mientras que los valores por debajo se entienden como silencio. Hay varias opciones para fijar el valor límite:
- Fijándola como una constante (esta constante puede utilizarse cuando el sonido se genera de la misma manera y en las mismas condiciones).
- Definir un número de valores que correspondan al silencio (si el silencio ocupa una parte importante de la grabación).
- Realizar un análisis de entropía (para ello es necesario determinar con qué intensidad "oscila" la señal dentro de un fotograma determinado. La amplitud de las oscilaciones en las partes silenciosas de una grabación suele ser menor).
De los tres, el análisis de entropía se considera el más fiable, aunque presenta defectos. Por ejemplo, la entropía puede disminuir cuando se pronuncian vocales o aumentar con un ligero ruido. Para resolver esta situación, se introducen dos conceptos: una "distancia mínima entre palabras" y una "longitud mínima de palabra". El algoritmo fusiona los fragmentos demasiado cortos y elimina el ruido.
3. Interpretación de las palabras
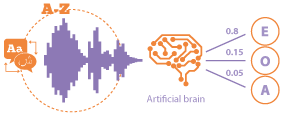 | Lo más frecuente es utilizar redes neuronales, combinadas con un aparato que contiene modelos ocultos de Markov, para interpretar las palabras. |
Modelos ocultos de Markov Mientras investigaba textos literarios de principios del siglo XX, el matemático Andrey Markov supuso inicialmente que la probabilidad de aparición de una letra dependía de la letra que la precedía. Resultó que este valor permanecía constante en distintas partes del mismo texto. | 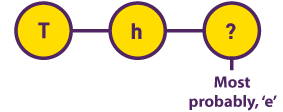 |
Los indicadores de probabilidad son únicos para cada autor. Esto permite utilizar modelos de Markov para detectar plagios.
En los modelos de Markov, el texto impreso consiste en secuencias de caracteres, mientras que el habla se trata como una secuencia de fonemas. Mientras que en el texto escrito se conocen todos los símbolos, las grabaciones de voz contienen la manifestación de los fonemas y no los fonemas en sí (por ejemplo, hay varias formas de pronunciar el sonido "R").
El aparato no sabe qué fonema se ha pronunciado; tan sólo percibe los parámetros de la onda sonora en un momento determinado. Además de estimar la probabilidad de que se produzca un fonema concreto, el sistema tiene que asociar los fonemas con las variantes de señal apropiadas.
Redes neuronales de avance
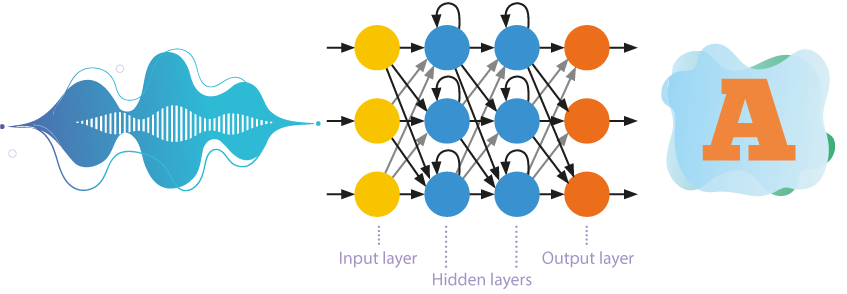
Hasta hace poco, las redes neuronales de autoaprendizaje con numerosas capas eran las más utilizadas en el reconocimiento de la voz.
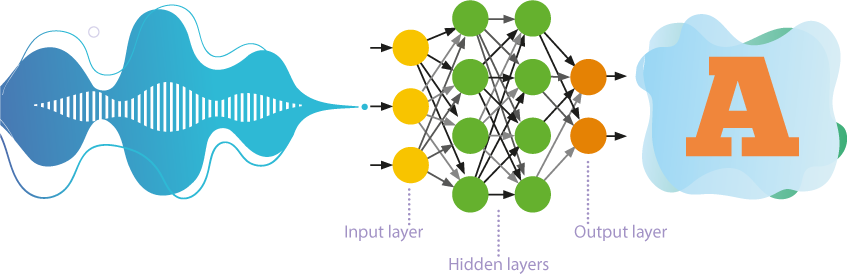
- Estas redes procesan la información en una sola dirección, es decir, de las neuronas de entrada a las de salida.
- Entre la entrada y la salida se sitúan jerárquicamente varias capas de neuronas, en las que los parámetros de un nivel superior se derivan de los parámetros de un nivel inferior.
- El autoaprendizaje o aprendizaje no supervisado implica que la red neuronal aprende a resolver problemas sin intervención externa. El enfoque revela patrones ocultos entre los objetos de la muestra de entrenamiento.
El resultado, que representa un conjunto de probabilidades de aparición de un fonema concreto, se compara con la predicción del modelo de Markov. El sonido pronunciado se determina con bastante precisión.
Redes neuronales recurrentes
Los sistemas de reconocimiento de voz se están alejando gradualmente del uso de modelos de Markov ocultos simplificados. Son cada vez más los modelos acústicos basados en redes neuronales recurrentes, que utilizan la memoria interna y la retropropagación para un reconocimiento más eficaz.
Las neuronas no sólo reciben información de la capa anterior, sino que también se envían a sí mismas los resultados de su propio procesamiento. Esto permite tener en cuenta el orden de aparición de los datos.
4. Fraseología
El principio de distinción entre frases y oraciones es muy similar al de la descodificación de palabras. Hasta ahora, para esta tarea se utilizaban modelos del tipo N-gram, en los que la probabilidad de aparición de una palabra en función de N palabras anteriores (usu. N = 3) se determinaba a partir del análisis de grandes bloques de texto. |  |
El aprendizaje profundo y el desarrollo de redes neuronales recurrentes mejoraron significativamente el modelo lingüístico y permitieron tener en cuenta el contexto de lo expresado. También desapareció la restricción de utilizar solo N palabras anteriores.
Los modelos lingüísticos eran ahora capaces de adivinar las palabras omitidas o no reconocidas por diversos motivos. Esto resultó ser especialmente importante en lenguas con un orden aleatorio de las palabras, como el ruso, donde no sólo eran importantes las palabras anteriores, sino toda la frase.
Así es como funcionan la mayoría de los sistemas de reconocimiento de voz. Pero no basta con entender lo que se dice. Para ser útil, el sistema también debe ser capaz de responder a las órdenes entrantes: tiene que responder a preguntas, abrir aplicaciones y gestionar otras funciones. De estas tareas se encargan los asistentes de voz.
Reconocimiento de voz del MAG425A
 | MAG425A incluye un mando a distancia controlado por voz y Google Assistant. La interfaz de voz proporciona una experiencia de usuario completamente nueva. Las principales funciones que realiza el asistente de voz incluyen
|
¿Qué es el Google Assistant?
Google Assistant (o Asistente de Google) es un asistente de voz virtual presentado por primera vez en la conferencia Google I/O 2016 celebrada en California. Al igual que Siri de Apple, Alexa de Amazon y Cortana de Microsoft, la aplicación ofrece información contextual a petición del usuario y es capaz de realizar determinadas acciones (como introducir consultas de búsqueda, establecer recordatorios, abrir aplicaciones y controlar la reproducción).
Google Assistant utiliza tecnología de aprendizaje asistido por ordenador y Procesamiento del Lenguaje Natural (PLN). El sistema es capaz de distinguir sonidos, palabras e ideas en el habla.
El Asistente funciona en mil millones de dispositivos y es compatible con más de treinta idiomas, pero la versión de Android TV sólo habla doce idiomas hasta ahora: inglés, francés, alemán, hindi, indonesio, italiano, japonés, coreano, portugués, español, sueco y vietnamita.

¿Cómo funciona Google Assistant?
En primer lugar, la aplicación graba las voces que detecta. Interpretar el habla requiere una gran capacidad de cálculo, por lo que el Asistente de Google envía solicitudes a los centros de datos de Google. Cuando estos datos llegan a uno de estos centros, la señal sólida se divide en sonidos. El algoritmo del Asistente de Google busca en una base de datos de sonidos del habla y determina qué palabras coinciden mejor con la combinación de sonidos registrada.
A continuación, el sistema selecciona las palabras "principales" del enunciado del usuario y decide cómo responder. Por ejemplo, si el Asistente de Google detecta palabras como "tiempo" y "hoy", responderá con la previsión del tiempo para hoy.
 | Los servidores de Google envían la información al dispositivo y la aplicación Asistente de Google realiza la acción deseada o responde con una voz. |
Google está cambiando la forma en que funciona Google Assistant para que se reconozca el habla y se procesen las órdenes directamente en el dispositivo del usuario. Utilizando las capacidades de las redes neuronales recurrentes, la empresa ha desarrollado un nuevo modelo de reconocimiento y comprensión del habla. El tamaño de la base de datos de modelos acústicos se ha reducido cien veces, por lo que la inteligencia artificial de Assistant ya puede trabajar a nivel local. La aplicación procesa el habla en tiempo real y casi sin demoras, incluso sin acceso a Internet. |  |
El Asistente de Google de nueva generación responde a una solicitud casi diez veces más rápido. Desde 2019, los nuevos modelos de smartphones Pixel de Google son compatibles con Google Assistant. En el futuro, la app también estará disponible en otros dispositivos.
Hoy en día, la interfaz de voz de Android TV está disponible no sólo para empresas con presupuestos millonarios, sino también para operadoras locales de IPTV/OTT. Esto supone una gran oportunidad para que las operadoras atraigan a nuevas audiencias, creen búsquedas de contenidos y accedan a los servicios de forma más fácil y cómoda para los usuarios, de modo que puedan destacar frente a sus competidores.
*Google y Android TV son marcas comerciales de Google LLC.
Recommended

Cómo mejorar la retención de espectadores con notificaciones push inteligentes
En el mercado IPTV actual, la competencia por la atención de los espectadores se ha vuelto tan intensa como la lucha por el contenido.

Cómo construir correctamente un entorno de staging para probar actualizaciones de IPTV
Cualquier actualización en un ecosistema IPTV afecta a múltiples componentes y puede impactar la autenticación, el inicio de canales, el EPG, VoD, DRM y la estabilidad de la red.

Nichos B2B para IPTV: de los hoteles a la televisión corporativa
IPTV está yendo cada vez más allá de los límites del negocio clásico de operadores y de la televisión para consumidores. Para el segmento B2B – desde hoteles y centros de negocios hasta instituciones médicas y oficinas corporativas – IPTV se está convirtiendo en una herramienta de servicio, comunicación y gestión de la atención.
